Abstract
In recent years, healthcare spending has risen and become a burden on many governments. There are multiple reasons for this increase such as overtesting, long medical treatment path, ignoring doctors’ orders, ineffective use of technologies, medical errors, many hospital readmissions, unnecessary emergency room (ER) visits, and medical treatment acquired side effects and infections. The first part of this editorial presents Healthcare Cost and Utilization Project (HCUP) datasets and their hierarchical partition used to build hierarchically structured personalized recommendation systems in healthcare domain. The second part outlines a simple strategy for reducing the number of readmissions using the concept of action rules to provide recommendations. First, we extract from HCUP datasets all possible procedure paths (course of treatments) for a given initial medical procedure. Then, we cluster patients according to the similarities in their diagnoses in order to increase the predictability of the course of treatment following this initial procedure. Finally, we present a novel algorithm that provides recommendations (actionable knowledge) to the physicians to put patients on a treatment path that would result in optimal reduction of the number of readmissions for these patients. There is not much research done on decreasing the number of readmissions to hospitals after initial procedure and almost none based on action rules.
Key words: recommendation systems, hospital readmissions, HCUP data, procedure graph, actionable knowledge
Introduction
There are many papers focused on predicting hospital readmissions,1, 2, 3, 4 especially predicting hospital admissions and readmissions to emergency or intensive care units.5, 6, 7, 8, 9, 10, 11 This editorial focuses on the basics of a knowledge-based recommendation system12, 13 for decreasing the number of readmissions to hospitals, based on actionable knowledge extracted from medical datasets, using the concept of action rules14, 15, 16 to provide recommendations. There is not much research done on decreasing the number of readmissions to hospitals after initial procedure and almost none based on action rules.8
This editorial presents the results obtained from mining the Florida State Inpatient Database (SID) that is a part of the Healthcare Cost and Utilization Project (HCUP17). The SID datasets are primarily a state-level discharge data collected from nonfederal community hospitals constituting most of the hospitals in the USA. The SID includes patients’ demographic data, such as race, age and gender. In addition to the demographic information, SID includes patients’ medical data, such as diagnoses and medical procedures. The main table in SID is the core table that contains over 280 features. Two types of coding schemes are used in the core table for labeling and formatting: (1) The International Classification of Diseases, 9th Revision, Clinical Modification (ICD-9-CM), (2) The Clinical Classifications Software (CCS). The ICD-9-CM coding uses more codes to label the procedures and diagnoses, whereas the CCS is a generalized and collapsed version of the ICD-9-CM. There are 15,072 diagnosis categories and 3948 procedure categories in the ICD-9-CM. Clinical Classifications Software clusters them into 285 diagnosis categories and 231 procedure categories.
Procedure graph
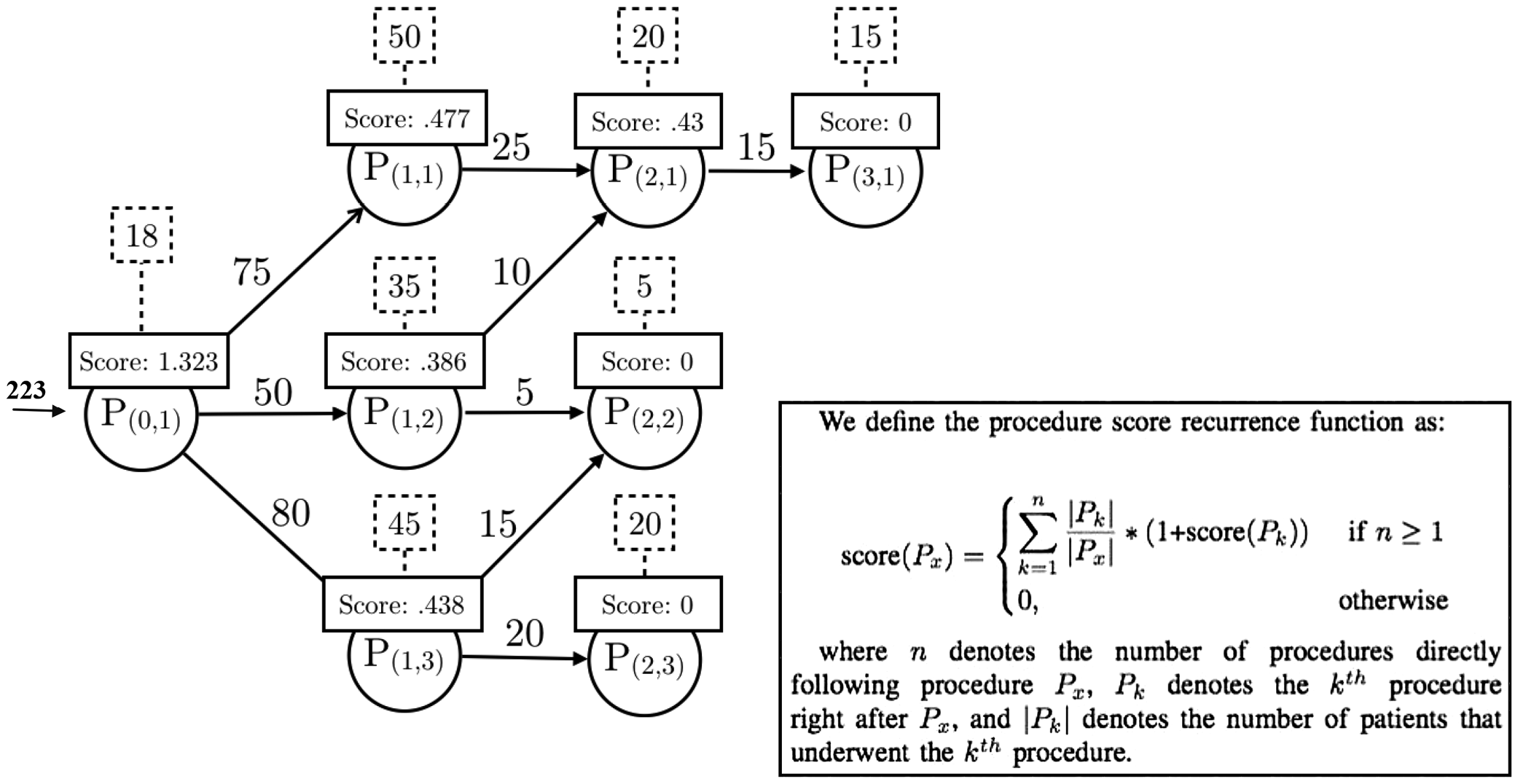
The ordered sequence of primary medical procedures representing procedure P followed by all procedures a single patient had after procedure P during the whole course of treatment in a hospital is called a procedure path for P.13
By a procedure graph,13 for a medical procedure P, we mean a directed graph representing a collection of all procedure paths for P extracted from the Florida SID, associated with patients during their course of treatment. The procedure graph can be used by physicians to visualize all possible outcomes which took place in Florida state hospitals after performing the initial procedure P. Nodes in the graph represent medical procedures that could be minor, such as breast biopsy, arthroscopy or laparoscopy, or that could be major, such as cesarean section, organ replacement or heart surgeries. The length of a path with a starting node P in a procedure graph gives the number of hospital readmissions after P. Figure 1 shows an example of the procedure graph for a procedure P(0,1). The numbers assigned to arrows represent the number of patients following that path and numbers in the dashed squares, above each procedure, represent the number of patients who had that procedure and did not come back to the hospital. Each node in a procedure graph is represented as term P(n,m), where n refers to the level of the node in a graph (distance from the initial node), which is the number of current readmissions, and m represents the path identifier.
For example, P(1,3) refers to the procedure node representing the 1st readmission to the hospital and belonging to the 3rd path in the procedure graph. Now, from the procedure graph, we can predict the most probable procedure path which follows the procedure P(i,j) for any i and j. Function “score” is used to evaluate nodes in the procedure graph (see Figure 1). The number of procedures directly following procedure Px is denoted by n, and |Pk| denotes the number of patients who underwent the kth procedure in a specific path. The Pk denotes the kth procedure right after Px.
The procedure score function assigned to a node in a procedure graph calculates the average number of readmissions after undergoing the procedure assigned to that node. It is a backward function which begins by assigning 0 score to all leaves of the procedure graph, which is the same as assigning 0 readmissions to them. Next, the procedure score function is calculated by moving backward until it reaches the starting node (initial procedure) of the graph. Figure 1 shows the scores assigned to all nodes in the procedure graph. The score 1.323 assigned to procedure P(0,1) means that the average number of readmissions for all patients who underwent this procedure is 1.323. It also means that 1.323 is the expected number of readmissions for a new patient scheduled to take procedure P(0,1).
Hierarchical clustering
The algorithm7 is hierarchical and splits patients recorded in HCUP data into clusters using the concept of positive and negative sets. The positive set (P-Set), also called the included set, is a set of diagnoses that a patient must exhibit in order to belong to a certain cluster. Similarly, the negative set (N-Set), also called the excluded set, is a set of diagnoses a patient cannot exhibit in order to belong to a given cluster. From now on, we will use notation (P-Set, N-Set) to define a cluster of patients recorded in HCUP data. For example, taking CCS coding, the label [{157}, {−3, −48}] identifies patients (on the 3rd level of granularity – 3 diagnoses are listed) having positive diagnosis 157 (included set) and negative diagnoses 3 and 48 (excluded set). In CCS coding, diagnosis 3 means bacterial infection, 48 means thyroid disorders, while 157 means acute and unspecified renal failure. More diagnoses are used in the labels, smaller are constructed granules and personalization is deeper.
The main goal of this clustering is to partition the patients into subgroups using their common characteristics as the filtering tool. Such process is called personalization of patients, which increases the predictability of the following procedures in the procedure graph and decreases the value of procedure score function (decreases the anticipated number of readmissions). Higher level of personalization is achieved by using labels containing more diagnoses and the same producing smaller granules. The number of generated clusters will keep increasing when granules are getting smaller. Therefore, there is a need to use a filtering technique to reduce the number of generated clusters. Clearly, if a majority of patients have a common diagnosis or do not have it, then this diagnosis will not play a significant role in determining the state in which the patients will end up. We tested 4 thresholds (5%, 10%, 15%, and 20%) and it looks like the optimal cut (in terms of generated clusters and time complexity) should be between 15% and 20%.
Reducing the number of readmissions
In this section, we present a new method for constructing medical recommendations to be used by physicians for placing a patient on the shorter, more successful and safer procedure path. The number of anticipated hospital readmissions will be decreased as well. Let us present an example based on Florida State HCUP dataset and CCS coding to explain how these recommendations are constructed.
Figure 2 refers to kidney transplant procedure. If a new patient is assigned to cluster 1 identified by label [{106}, {−53, −156}], then we cannot enhance the patient’s medical status, as this cluster has the minimum score among the 3 clusters shown in Figure 2. However, if a patient belongs to any of the 2 remaining clusters, then we can provide a medical recommendation allowing the patient to follow the same path as patients in cluster 1. If we do that, the number of readmissions for this patient should decrease by 48%–52%.
The interpretation for all recommendation actions used in Figure 2 is as follows:
• (d → d): keep diagnostic code d for patients in the desired cluster;
• (∼ → −d): patients in the desired cluster cannot have diagnostic code d;
• (d → −d): diagnostic code d has to be treated;
• (∼ → d): patients in the desired cluster need to have diagnostic code d.
The largest gain in the procedure score is achieved by following the recommendations for patients assigned to cluster 3 identified by label [{53, 106}, {−3}], which will move them to cluster 1. These patients additionally cannot have disorder 156.
The recommendation that the system will provide to the physician is to treat diagnostic code 53 (53 → −53) for patients in cluster 3 who do not have disorders identified by diagnostic code 156. By following this recommendation, patients in cluster 3 should end up with the same outcomes as patients in cluster 1. It is worth mentioning that lifestyle changes and drugs are sufficient to treat disorder 53. This will result in 0.5 reduction of hospital readmissions scoring function for these patients (see Figure 2).